How to validate DataFrame joins in Python
Ever spent too much time debugging a data issue, only to realize it was caused by a join where the keys weren’t actually unique?
Turns out, both polars AND pandas have a simple fix for that: the validateargument in the .join() method. It allows to detect duplicate keys early on, throwing an exception if the uniqueness condition is not met, thus saving us from data explosions passing through silently an causing havoc downstream.
Best part? Implementing this is less than one extra line of code!

The default value for validate is "m:m" (many-to-many), which eans no checks are performed, but we can enable them easily by changing the argument value to:
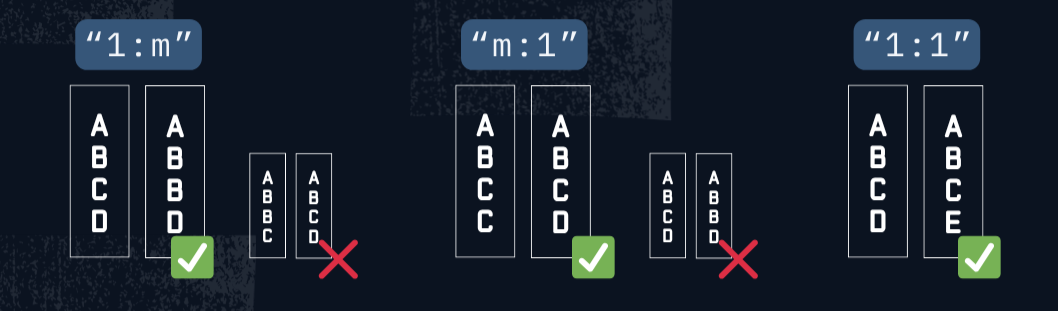
"1:m"(one-to-many): checks uniqueness in the left DataFrame’s join key(s)."m:1"(many-to-one): checks uniqueness in the right DataFrame’s key(s)."1:1"(one-to-one): checks the uniqueness of join keys in both DataFrames.
If the uniqueness constraints are not met, an error will be raised (we’ll see an exception.ComputeError if we’re using the method with polars).
Below we can see an example of how to use validate with joins in polars:
import polars as pl
catalog = pl.DataFrame({
"product_id": [1, 2, 3],
"product_name": ["Laptop", "Mouse", "Keyboard"]
})
# Pricing table — contains conflicting information for product_id=2
prices = pl.DataFrame({
"product_id": [1, 2, 2, 3],
"price": [1500, 25, 20, 50]
})
catalog.join(prices, on="product_id", how="left", validate="1:1")
In this example, the code will generate the following error:
polars.exceptions.ComputeError: join keys did not fulfill 1:1 validation
If we want to handle the error gracefully, we can wrap the join code in a try/except block. This allows us to inspect the keys that violated the uniqueness constraint, log the issue or take some other action.
try:
catalog.join(prices, on="product_id", how="left", validate="1:1")
except pl.exceptions.ComputeError as e:
print("❌ Join validation failed:", e)
print("\n🔍 Checking duplicates in the right table:")
dupes = prices.group_by("product_id").len().filter(pl.col("len") > 1)
print(dupes)
❌ Join validation failed: join keys did not fulfill 1:1 validation
🔍 Checking duplicates in the right table:
shape: (1, 2)
┌────────────┬─────┐
│ product_id ┆ len │
│ --- ┆ --- │
│ i64 ┆ u32 │
╞════════════╪═════╡
│ 2 ┆ 2 │
└────────────┴─────┘
If you’re using pandas instead of polars (😬😅), the code is almost the same, provided you’re using version 1.5.0 or later (and you can still add the check to the .merge method):
import pandas as pd
catalog = pd.DataFrame({
"product_id": [1, 2, 3],
"product_name": ["Computer", "Mouse", "Keyboard"]
})
prices = pd.DataFrame({
"product_id": [1, 2, 2, 3],
"price": [1500, 25, 20, 50]
})
try:
catalog.merge(prices, on="product_id", how="left", validate="one_to_one")
except pd.errors.MergeError as e:
# (error handling logic)